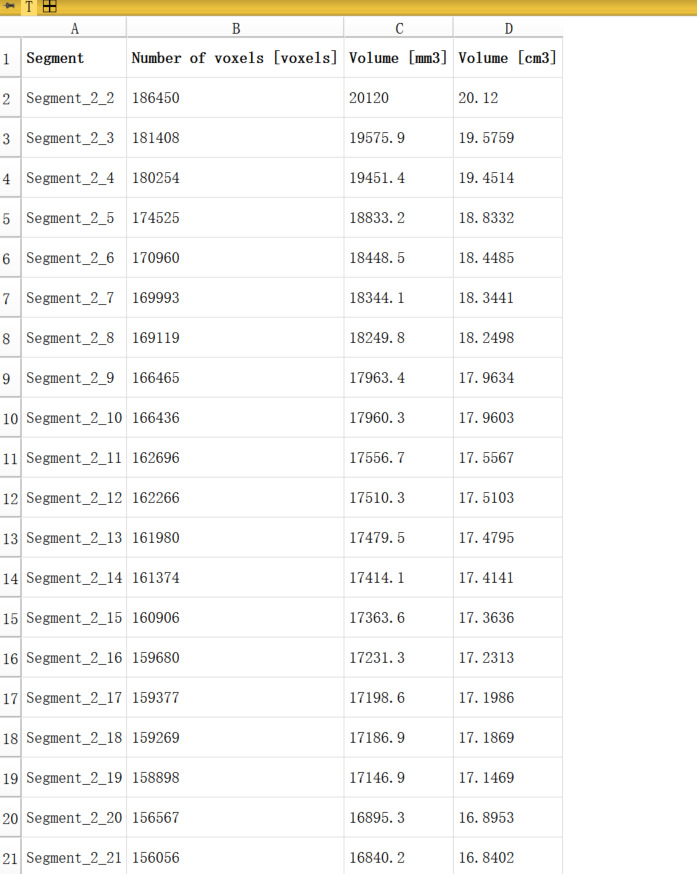
从截图来看,数据表中的分割区域(Segment)是按照名称(如 Segment_2_2、Segment_2_3)进行排序,而不是体积大小排序。如果你希望根据位置信息(比如解剖学顺序或某种特定规则)对这些数据重新排序,以下是一些方法:
方法 1:基于名称排序
如果名称中隐含了位置信息(如序号 Segment_2_2、Segment_2_3 表示位置顺序),可以直接按名称排序。
- 检查名称是否符合逻辑顺序。
- 按列
Segment排序(默认行为应该就是按照名称的自然顺序排序)。
方法 2:根据位置信息排序
如果位置信息(如分割对应的坐标中心)另存于其他文件或在 Slicer 的分割数据中,可以按以下方式操作:
-
提取位置信息:
- 在3D Slicer中,使用 Segment Statistics 模块导出分割区域的质心(Centroid)。
- 质心信息可导出为表格文件,包含每个分割的
(x, y, z)坐标。
-
合并与排序:
- 将质心数据合并到当前表格。
- 根据
z坐标(冠状位通常是纵向坐标)或其他指定的排序规则进行排序。
方法 3:脚本自动排序
如果需要在3D Slicer中自动化排序,可使用以下Python代码片段(在 Slicer 的 Python Interactor 中运行):
import pandas as pd
# 模拟导入数据表
data = {
"Segment": ["Segment_2_2", "Segment_2_3", "Segment_2_4", "Segment_2_5"],
"Volume [cm3]": [20.12, 19.5759, 19.4514, 18.8332],
"Centroid_Z": [150.0, 145.0, 155.0, 140.0] # 假设质心Z坐标
}
# 转换为DataFrame
df = pd.DataFrame(data)
# 按质心Z排序
df_sorted = df.sort_values(by="Centroid_Z", ascending=True)
# 输出排序结果
print(df_sorted)
运行后即可得到按位置信息(如质心坐标)排序的结果。
总结
从你的截图来看,当前排序是按照名称(Segment_2_X)进行的。如果位置信息是隐含在名称中,默认排序即可。如果需要更复杂的位置信息排序(如质心),则需要先导出位置信息再排序。你可以提供更详细的数据(如质心或分割规则),我可以帮助进一步调整排序方法!