一、MONAI Label 智能分割模块简介
这几年,3D 医学图像的智能分割已经从“演示项目”变成很多科室日常工作的重要工具。在 3D Slicer 生态里,MONAI Label 是目前官方主推的智能分割平台,它的几个特点非常适合临床医生、科研人员上手:
- 后端是一个 AI 标注与推理服务器 (MONAI Label Server),可以部署在本地 GPU 工作站或科室服务器上;
- 前端通过插件接入:3D Slicer、OHIF、QuPath、CVAT 等都可以直接连这台 Server;
- 同时支持:
- 预训练模型的一键自动分割(Auto-Segmentation)
- 交互式分割(DeepEdit / DeepGrow 等)
- 主动学习闭环(标注 → 送回服务器 → 增量训练 → 再推理)。
对我来说,它最吸引人的点有两个:
- 完全开源,可以在本地医院内网独立部署,不依赖公共云服务;
- 可以用我们自己的病例数据训练模型,适配本地人群和本院设备,适合作为科研 + 教学 + 质控 的一套统一平台。
二、本地部署对硬件的大致要求
这一节更像是“选型参考”和“踩坑提醒”,不是严格的官方标准,也 不构成对任何具体显卡型号的购买建议 。不同任务(模型大小、图像分辨率、是否训练)对硬件消耗差别很大,建议先在现有设备上小规模试跑,再决定是否升级。
1. 操作系统与基础环境
- 操作系统 :
- 建议:Windows 10 / 11 64 位专业版或企业版。
- 需要具备安装 NVIDIA 官方显卡驱动、Miniconda、开发工具等的网络环境和权限。
- 磁盘 :
- 系统盘与数据盘均建议为 SSD。
- 为 Conda 环境、模型权重和病例数据预留至少 50–100 GB 空间(越多越好)。
2. 显卡(GPU)与显存建议(重点)
MONAI Label 基于 PyTorch,3D 医学影像分割对 GPU 显存非常敏感。下面是经验性的分档建议,仅供参考:
① 已有中端显卡(“能跑起来”的最低经验档)
-
条件示例:
* NVIDIA GTX / RTX 系列,显存约 6–8 GB ,支持 CUDA; -
预期用途:
* 可以尝试部署 MONAI Label,跑通 radiology 等 示例 App 的基础推理 ;
* 对单例、分辨率适中的病例做自动分割、简单交互式分割; -
限制与风险:
* 大体积 3D 数据(高分辨率 CT/MR)、复杂模型或训练流程容易显存不足(OOM);
* 推理时间较长,不适合高并发、多用户同时使用。
② 推荐级别(适合作为科室日常试用/教学环境)
-
条件示例:
* NVIDIA RTX 系列,显存 8–12 GB 及以上 (如部分 RTX 3060 / 4060 / 4070 级别); -
预期用途:
* 可以较为顺畅地使用 radiology App 做多例 3D CT/MR 分割;
* 可以尝试一定规模的模型微调或增量训练(batch size 适当控制); -
注意事项:
* 仍需根据任务调节 patch 大小、网络结构,避免一味堆模型导致显存爆掉。
③ 高配工作站(科研训练 + 教学演示环境)
-
条件示例:
* NVIDIA RTX 40 / 50 系列,显存 16 GB 及以上 ; -
预期用途:
* 用于教学演示、科研训练、较复杂模型的实验;
* 支持多模型并行、多人在局域网内共享同一 MONAI Label Server。
重要提醒 :不同显卡在不同驱动版本、CUDA 版本、具体模型配置下表现差异很大。上述仅为经验范围,并不能保证“某一个具体型号一定可用或一定流畅”。如涉及设备采购,请结合计算机专业人员的评估意见综合决策。
3. 内存(RAM)与 CPU
- 内存(RAM)
- 最低建议:16 GB (仅做小规模推理、演示用)。
- 推荐配置:32 GB 及以上 (3D 体数据加载、预处理、并行任务更从容)。
- 用于科研训练或同时运行多个服务(如 Slicer + MONAI Label + 其它工具),建议 64 GB 。
- CPU
- 主流多核桌面 CPU 基本足够(如 Intel i5/i7 或同档次 AMD),MONAI 主要吃 GPU;
- 核心数越多,对数据预处理、多进程加载有一定帮助,但远不如 GPU 关键。
4. 显卡驱动与 CUDA 相关
- 需要安装 NVIDIA 官方显卡驱动 ,并保证与 PyTorch 对应的 CUDA 版本兼容;
- 建议做法:
- 先安装/更新显卡驱动;
- 在 Conda 环境中,严格按照 PyTorch 官网提供的命令安装对应 CUDA 版本的
torch(如本教程使用的 CUDA 12.8 轮子)——不要手动额外装系统级 CUDA toolkit,以免版本冲突。
5. 本文示例环境说明(实际演示用的是哪一档)
本文后续的“部署全过程”全部是在以下环境下完成和验证的:
- 操作系统:Windows 11 专业版 64 位
- GPU:NVIDIA GeForce RTX 5080 16 GB 显存
- 内存:64 GB RAM
- 磁盘:系统盘 + 数据盘均为 SSD
- 软件环境:Miniconda + Python 3.10 + PyTorch(CUDA 12.8)+ MONAI Label 0.8.5
请把本文视为一份“在高配工作站上跑通 MONAI Label 的实战记录”,并非对任意显卡型号的适用性和性能做出保证。建议读者先在现有机器上按文中步骤小规模测试 radiology 示例 App,确认可用后,再视情况考虑硬件升级或服务器部署。
三、一台 RTX 5080 电脑上的完整部署记录
- 在一台装有 NVIDIA GeForce RTX 5080(16 GB) 的 Windows 11 专业版操作系统上
- 用 Miniconda + Python 3.10 搭建一个独立环境
- 安装 PyTorch(CUDA 12.8)+ MONAI Label 0.8.5
- 下载官方 radiology 示例 App
- 成功启动本机的 MONAI Label Server ,浏览器访问:
http://127.0.0.1:8000
能够看到 MONAILabel 的 OpenAPI 页面,并且后续可以在 3D Slicer 里通过 MONAI Label 扩展直接连接这台服务器进行智能分割。
下面是我这次在本地(Windows 11 + RTX 5080)完整部署 MONAI Label Server 的全过程整理,所有命令都放在代码块里方便复制。
第 1 步:确认 GPU 与驱动状态
1.1 图形界面快速确认
先用任务管理器确认显卡是否正常工作:
- 右键任务栏空白处 →【任务管理器】。
- 切换到【性能】标签页。
- 左侧选择【GPU 1】。
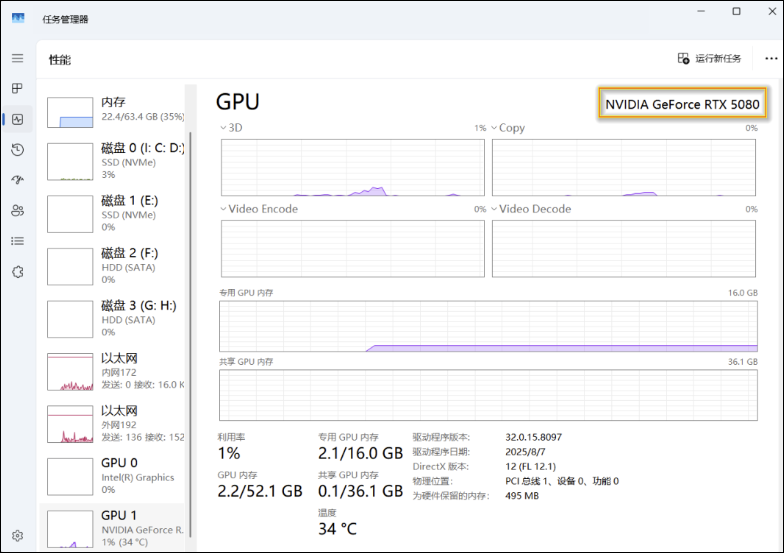
- 名称显示为 NVIDIA GeForce RTX 5080
- 可见有 3D / Copy / Video Encode 等曲线在变化
说明显卡和驱动大体正常。
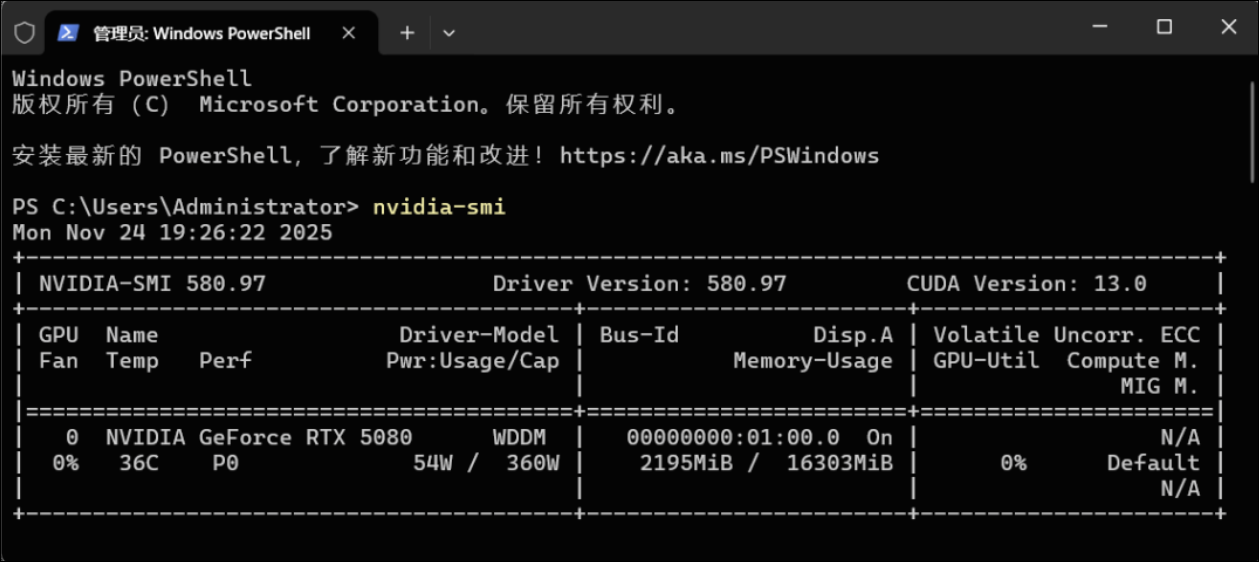
1.2 用 nvidia-smi 严谨检查
在命令行用 NVIDIA 官方工具确认驱动和 CUDA 版本:
- 按
Win + X→ 选择【终端(管理员)】。 - 在窗口中输入:
nvidia-smi
输出中重点看三项:
Driver Version:580.97CUDA Version:13.0GPU一栏显示:NVIDIA GeForce RTX 5080
到这里可以确认:GPU + 驱动没有问题,可以装深度学习环境了。
第 2 步:安装 Miniconda(给 MONAI 单独建环境)
我不想动系统里已经装好的 Python,所以选择用 Miniconda 管理虚拟环境。
2.1 下载 Miniconda
打开浏览器,在地址栏输入:
https://www.anaconda.com/download
页面中往下找到 “Miniconda Installers” ,在 Windows 这一栏选择:
- 64-bit
- Python 3.13(installer 会带一个 3.13 的基础环境,但后面我会在它上面再建 3.10 的虚拟环境)
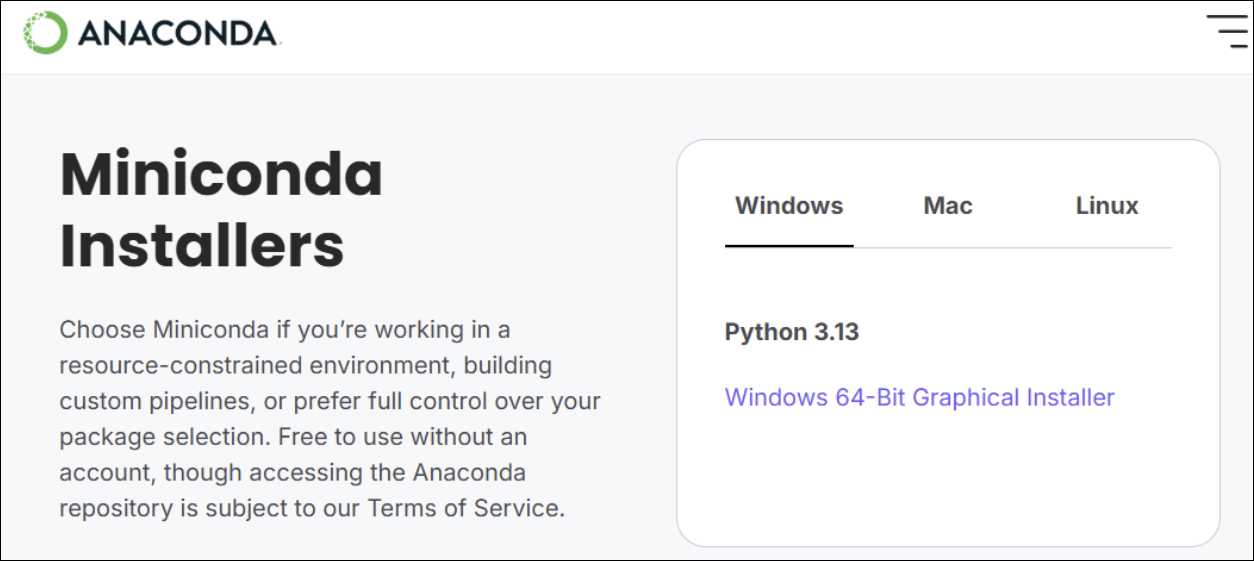
下载得到一个类似下面文件名称的安装程序。
Miniconda3-py313_25.9.1-3-Windows-x86_64.exe
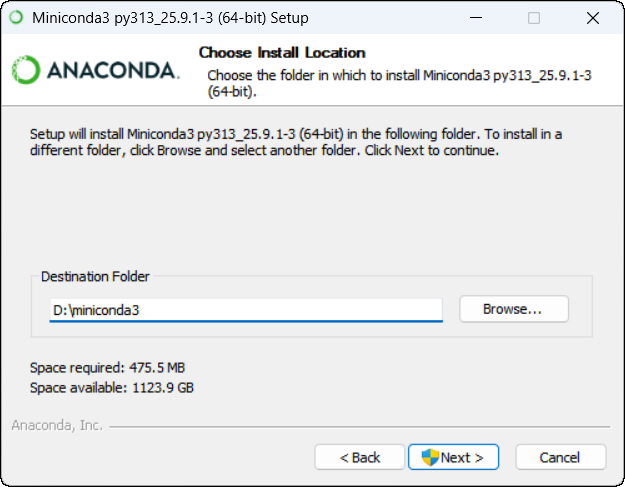
2.2 安装路径选择
双击安装程序后,在 “Destination Folder” 这一页:
- 改路径到 D 盘 (SSD盘1T,避免把一大堆包装在 C 盘):
D:\miniconda3
- 路径中不包含空格和中文,后面配置环境就省心很多。
2.3 高级选项勾选
“Advanced Installation Options” 页面,建议勾选三个选项:

Create shortcuts-
Register Miniconda3 as the system Python 3.13 -
Clear the package cache upon completion
然后点击 Install ,等待安装完成 → Finish 退出。
2.4 检查 Conda 是否可用
在开始菜单搜 “Anaconda Prompt”,打开后输入:
conda --version
终端输出类似:
(base) C:\Users\Administrator>conda --version
conda 25.9.1
说明 Miniconda 安装成功,可以在开始菜单找到Anaconda Prompt,右键点击固定到任务栏。
第 3 步:创建 MONAI Label 专用环境(Python 3.10)
MONAI + PyTorch 在 3.10 上最稳,需要专门建了一个 3.10 的环境。
3.1 创建 monailabel 环境
在 Anaconda Prompt(前缀是 (base) )里输入:
conda create -n monailabel python=3.10
连续输入3次“a”表示接受
接着会出现一长串将要安装的包列表,最后问:
Proceed ([y]/n)?
输入:
y
等待环境创建完成。
3.2 激活环境
创建结束后,在同一个终端输入:
conda activate monailabel
提示符变成:
(monailabel) C:\Users\Administrator>
这表示已经进入了新的monailabel
环境,后续所有安装都发生在这里,不会污染系统其他 Python。
第 4 步:在 monailabel 环境中安装 PyTorch(CUDA 版)
按 PyTorch 官网的推荐方式,直接用 CUDA 12.8 的官方仓库。
在 (monailabel) 环境中执行:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
这条命令会:
- 从
cu128仓库下载带 CUDA 12.8 的 PyTorch、torchvision、torchaudio - 自动选择适配 Python 3.10 + Windows 的 wheel
等待它跑完,看到结尾类似:
Successfully installed MarkupSafe-2.1.5 filelock-3.19.1 fsspec-2025.9.0 jinja2-3.1.6 mpmath-1.3.0 networkx-3.3 numpy-2.1.2 pillow-11.3.0 sympy-1.14.0 torch-2.9.1+cu128 torchaudio-2.9.1+cu128 torchvision-0.24.1+cu128 typing-extensions-4.15.0
(monailabel) C:\Users\Administrator>
说明
GPU 版 PyTorch 已经装好 。
第 5 步:测试 PyTorch 是否识别 GPU(CUDA)
5.1 进入 Python 解释器
python
回车后,你会看到类似:
(monailabel) C:\Users\Administrator>python
Python 3.10.19 | packaged by Anaconda, Inc. | (main, Oct 21 2025, 16:41:31) [MSC v.1929 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>
说明已经进入 Python 解释器。
5.2 运行自检代码
在 Python 里输入以下三行(逐行回车)
import torch
print(torch.__version__)
print("CUDA available:", torch.cuda.is_available())
print("GPU name:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "None")
预期输出类似:
>>> import torch
>>> print(torch.__version__)
2.9.1+cu128
>>> print("CUDA available:", torch.cuda.is_available())
CUDA available: True
>>> print("GPU name:", torch.cuda.get_device_name(0) if torch.cuda.is_available() else "None")
GPU name: NVIDIA GeForce RTX 5080
只要:
-
CUDA a vailable: 一行是 True
-
GPU name 能正确显示 RTX 5080
就说明 PyTorch 已经可以正常调用你的显卡。
5.3 退出 Python
exit()
回到命令行:
(monailabel) C:\Users\Administrator>
第 6 步:在 monailabel 环境中安装 MONAI Label
按****照官网推荐方式,用 pip 安装 MONAI Label。
请确认当前命令行前缀仍然是:
(monailabel) C:\Users\Administrator>
6.1 用 pip 安装最新 MONAI Label
在 Anaconda Prompt 窗口中输入:
pip install -U monailabel
-U表示如果已有旧版就升级到最新版。安装过程会自动拉取 MONAI 框架及其它依赖。
等待它完整跑完,直到再次回到
(monailabel) C:\Users\Administrator>
6.2 检查版本号
安装结束后,用一行命令确认版本:
python -c "import monailabel; print(monailabel.__version__)"
输出:
0.8.5
说明环境中已经有
MONAI Label 0.8.5 。
第 7 步:下载 radiology 示例 App,并准备数据目录
MONAI Label 官方自带多个 App,其中 radiology 是最常用、也最适合入门演示的。我打算用下面这套目录结构,方便记忆:
- App 代码:
D:\MONAILabel\Apps\radiology
- 病例数据:
D:\MONAILabel\Data\radiology_studies
7.1 创建目录
在资源管理器里手动创建:
D:\MONAILabel\Apps
D:\MONAILabel\Data
D:\MONAILabel\Data\radiology_studies
其中
radiology_studies
暂时可以是空目录,后面再往里放数据。
7.2 在 monailabel 环境下载 radiology App
回到 Anaconda Prompt(前缀仍然是 (monailabel) ):
- 打开 Anaconda Prompt,确保前缀是:
(monailabel) C:\Users\Administrator>
如果显示为
(base) C:\Users\Administrator>
需要执行下方的命令
conda activate monailabel
- 切换到 Apps 目录:
切换到 Apps 目录:
cd /d D:\MONAILabel\Apps
运行 MONAI Label 官方推荐的 radiology App 下载命令(输出到当前目录),复制时后面的“.”不要遗漏:monailabel apps --download --name radiology --output .
执行后终端提示:
(monailabel) D:\MONAILabel\Apps>monailabel apps --download --name radiology --output .
Using PYTHONPATH=D:\miniconda3\envs;
""
radiology is copied at: D:\MONAILabel\Apps\radiology
(monailabel) D:\MONAILabel\Apps>
此时在资源管理器中看到:
D:\MONAILabel\Apps\radiology\
到这里,
radiology App 已经就位 。
第 8 步:解决 pydicom 版本不兼容的问题
第一次启动 Server 时,我踩到了一个兼容性坑,这一步非常关键。
8.1 首次启动时出现的报错
我最初用下面的命令启动 Server:
monailabel start_server --app "D:/MONAILabel/Apps/radiology" --studies "D:/MONAILabel/Data/radiology_studies" --host 0.0.0.0 --port 8000
结果终端报错(摘关键部分):
File ".../pydicom_seg/reader.py", line 9, in <module>
from pydicom._storage_sopclass_uids import SegmentationStorage
ModuleNotFoundError: No module named 'pydicom._storage_sopclass_uids'
问题的核心是:
- 环境里被自动装的是 pydicom 3.x ;
- 但
pydicom_seg这个库仍然引用了 pydicom 旧版的内部模块_storage_sopclass_uids,在 3.x 已经被删除。
所以我需要把 pydicom 降级到 2.x 中的一个稳定版本。
8.2 把 pydicom 降级到 2.4.4
在同一个 (monailabel) 环境里执行:
pip install "pydicom==2.4.4" --force-reinstall
安装过程中 pip 提示:
pynetdicom 3.0.4 requires pydicom<4,>=3, but you have pydicom 2.4.4 which is incompatible.
这只是说
pynetdicom 希望 pydicom≥3 ,而我现在用的是 2.4.4。但当前这个部署场景我并没有用到 DICOM 网络传输(pynetdicom),只用本地文件,所以这条警告可以暂时忽略 。
8.3 自检:确认 pydicom 与 pydicom_seg 能共存
用一行命令快速验证:
python -c "import pydicom, pydicom_seg; print('pydicom', pydicom.__version__)"
输出:
pydicom 2.4.4
且没有报错,说明:
- pydicom 已成功降级为 2.4.4
pydicom_seg可以正常导入
至此,与 _storage_sopclass_uids 相关的兼容性问题已经解决 。
第 9 步:正确启动 MONAI Label Server
再启动 Server 时我又遇到一条提示,也在这里一并写清楚。
9.1 radiology App 要求明确指定要启用的模型
再次启动时,日志中出现了这样一段:
Provide --conf models <name>
Following are the available models. You can pass comma (,) separated names to pass multiple
all, deepedit, deepgrow_2d, deepgrow_3d, localization_spine, localization_vertebra, segmentation, segmentation_spleen, segmentation_vertebra, sw_fastedit
...
SystemExit: -1
这不是错误,而是 radiology App 的保护机制 :如果我没有通过 --conf 指出要加载哪些模型,它就不会继续启动,而是直接 exit(-1) 。
9.2 最终的“一行版”启动命令(单模型 / 多模型 / 全部模型)
我选了最简单、最典型的 spleen 分割模型 来做演示,于是把命令改成一行写完:
monailabel start_server --app "D:/MONAILabel/Apps/radiology" --studies "D:/MONAILabel/Data/radiology_studies" --conf models segmentation_spleen --host 0.0.0.0 --port 8000
几个要点:
1. 一行写完 建议整条命令写成一行,不再使用 ^ 做续行,避免换行符或空格弄错导致参数被截断。
2. 只启用单个模型的写法
例如只启用脾脏分割模型 segmentation_spleen :
--conf models segmentation_spleen
整体命令就是前面那条完整的一行。
3. 同时启用多个模型的写法
如果希望 radiology App 同时加载多个模型(例如脾脏分割 + DeepEdit),可以用逗号分隔模型名:
--conf "models segmentation_spleen,deepedit"
完整示例:
monailabel start_server --app "D:/MONAILabel/Apps/radiology" --studies "D:/MONAILabel/Data/radiology_studies" --conf "models segmentation_spleen,deepedit" --host 0.0.0.0 --port 8000
如果分行书写则如下:
monailabel start_server ^
--app "D:/MONAILabel/Apps/radiology" ^
--studies "D:/MONAILabel/Data/radiology_studies" ^
--conf "models segmentation_spleen,deepedit" ^
--host 0.0.0.0 ^
--port 8000
4. 启用 radiology App 中所有可用模型的写法
radiology App 会在启动时列出支持的模型列表(包括 deepedit、deepgrow_2d、deepgrow_3d、segmentation_spleen 等)。如果希望一次性启用所有这些模型,可以把 models 的值设为 all :``
--conf models all
完整示例:
monailabel start_server --app "D:/MONAILabel/Apps/radiology" --studies "D:/MONAILabel/Data/radiology_studies" --conf models all --host 0.0.0.0 --port 8000
这种写法适合做综合演示,但首次启动会按需加载所有模型,初始化时间会稍微长一些。
执行成功后,终端最后几行日志变成:
Timeloop now started. Jobs will run based on the interval set
Application startup complete.
Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
说明
Server 已经成功启动 ,此时这个终端窗口要一直保持打开。
第 10 步:浏览器检查 Server 是否可访问
最后,我在浏览器里做了一个连通性测试:
-
打开 Edge / Chrome。
-
地址栏输入:
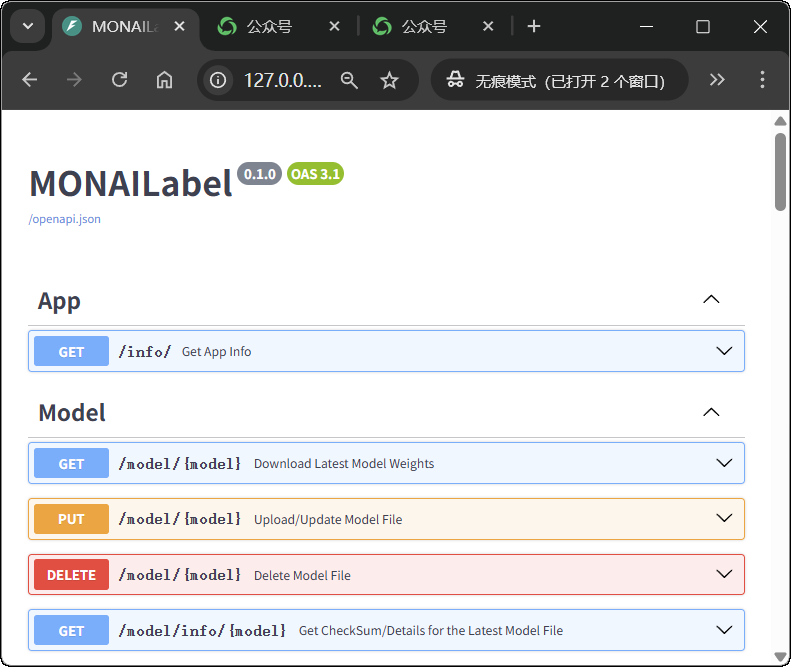
http://127.0.0.1:8000
- 页面出现 “MONAILabel – APIs ” 的 Swagger / OpenAPI 文档界面,包含
/info/、/model/{model}等接口说明。
这一步确认了三件事:
- MONAI Label Server 正常在 本机 8000 端口 监听;
- radiology App 与配置加载完成;
- 后续 3D Slicer 只要填
http://127.0.0.1:8000就可以连接这个 Server。
部署完成后的“自查清单”
我最终把本机部署成功时的关键状态总结成了一份清单,方便以后回顾,也方便大家进行对照:
1)环境信息
- Conda 环境:
monailabel - Python 版本:3.10.19
- 关键包版本:
torch 2.9.1+cu128
torchvision 0.24.1+cu128
torchaudio 2.9.1+cu128
monailabel 0.8.5
pydicom 2.4.4
2)目录结构
D:\MONAILabel\
├─ Apps\
│ └─ radiology\ # 官方 radiology App 代码
└─ Data\
└─ radiology_studies\ # 本地病例数据(可以先为空)
3)必要的兼容性修正
在 monailabel 环境中执行过:
pip install "pydicom==2.4.4" --force-reinstall
目的是避免下方的报错
ModuleNotFoundError: No module named 'pydicom._storage_sopclass_uids'
4)最终启动命令
monailabel start_server --app "D:/MONAILabel/Apps/radiology" --studies "D:/MONAILabel/Data/radiology_studies" --conf models segmentation_spleen --host 0.0.0.0 --port 8000
5)运行状态判断
- 终端最后几行包含:
Application startup complete.
Uvicorn running on http://0.0.0.0:8000
浏览器访问
http://127.0.0.1:8000
- 能看到 MONAILabel 的 API 文档页面。
到这里,这台 RTX 5080 电脑上的 MONAI Label Server 就算真正部署完毕 ,后续只需要在 3D Slicer 里安装 MONAI Label 扩展,并在浏览器中将 Server地址填写为:
http://127.0.0.1:8000
就可以开始在 Slicer 中使用 radiology App 做智能分割了。

